Published: 21.11.2025

From the book Software Architecture: The Hard Parts by Neal Ford, Mark Richards, Pramod Sadalage and Zhamak Dehghani O’Reilly Media, August 2022.
Database types
Since 2005, a ton of new databases have popped up, which means picking one isn’t as simple as it used to be, there’s just so much choice, and every option has its own pros and cons. To help figure things out, architects look at stuff like how easy a database is to learn, how flexible the data modeling is, how well it handles lots of traffic, its reliability, consistency, programming language support, and community size. Each database gets star ratings in these areas, so you can quickly see which one matches your needs best.
Relational Databases:
Relational databases (RDBMS) have been a popular choice for over thirty years due to their stability and business value. They use SQL, support ACID transactions, and are easy to learn, model, and widely supported, but scaling them for high traffic can be more complex compared to newer database types. Popular examples include MySQL, Oracle, SQL Server, and PostgreSQL.
Relational databases are widely used for business applications like inventory management in retail, electronic medical records in healthcare, banking transactions in finance, e-commerce order tracking, HR and CRM systems in enterprises, and supply chain management. They help store and organize structured information with strong data consistency, making them perfect for operations that need reliable transactions and complex data relationships. Popular examples include tracking customer accounts in banks, managing patient records in hospitals, handling product catalogs in online stores, and supporting customer interaction logs in CRM software.

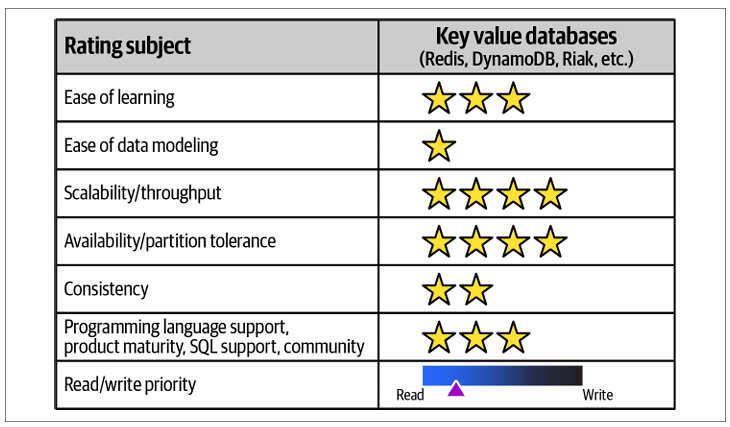
Key-Value Databases
Key-value databases store data as simple key-value pairs, making them easy to use and fast for lookups. They work well for caching and session storage, handle scaling easily, and let you trade off consistency for performance; however, they don’t support complex queries or data relationships like relational databases. Popular examples are DynamoDB, Riak KV, Redis, and MemcacheDB.
Key-value databases are used for caching, session management, storing user profiles, managing shopping carts in e-commerce, and real-time analytics. They’re also popular for storing IoT sensor data, gaming leaderboards, product catalogs, and personalized recommendations in social media apps. Examples include Redis for fast in-memory caching, DynamoDB for scalable cloud storage, and Couchbase for flexible product data.
Document Databases
Document databases store data as human-readable documents (like JSON or XML) and offer flexible schemas with indexable attributes, making them easier to model and query compared to key-value stores. They scale well horizontally and support configurable consistency but can be complex to set up when sharded. Popular for their ease of learning and strong community support, document databases often prioritize read performance with secondary indexes. They’re great for content management, APIs, and applications with evolving data structures.
Document databases are used in real-world scenarios like customer 360 views that combine data from various sources to create comprehensive customer profiles for personalized marketing. They are popular in content management systems for handling diverse media and formats, and in real-time analytics and IoT applications to process streaming data effectively. Document databases also shine in mobile and web apps that need flexible, rapidly changing schemas and in e-commerce for personalized product catalogs and recommendations. Examples include MongoDB, Couchbase, and Amazon DocumentDB, widely adopted in industries for their scalability and ease of use.

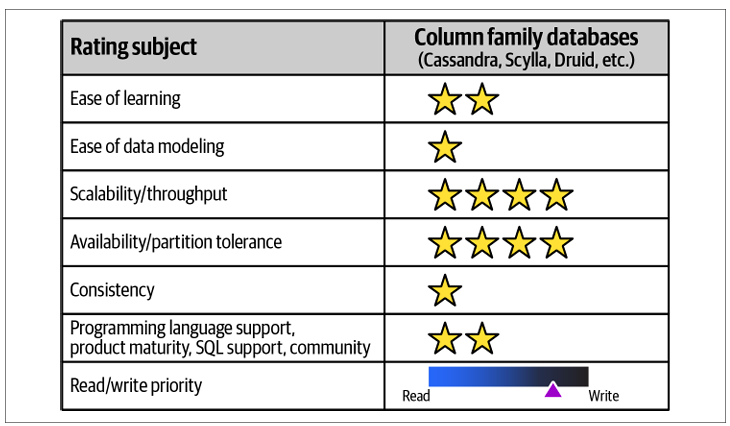
Column Family Databases
Column family databases, also called wide column or big table databases, store data as rows with varying sets of columns that are name-value pairs, grouped by a row key. They are powerful for handling large-scale, sparse data with high write throughput and horizontal scalability, naturally operating in clusters for high availability. Examples include Apache Cassandra and HBase, often used for event logging, content management, and time-series data where fast writes and flexible column arrangements are critical.
Column family databases like Apache Cassandra are used in many real-world scenarios requiring high scalability and write throughput. Common uses include:
- Real-time analytics for financial services, e-commerce, and telecommunications to monitor customer behavior and detect fraud.
- Managing massive IoT sensor data streams, supporting edge computing and device data aggregation.
- Catalog and inventory management in retail and logistics, enabling fast, reliable product information updates globally.
- Message queuing systems supporting asynchronous communication in distributed architectures.
- Event logging and tracking for compliance, operational monitoring, and security analysis with fault-tolerant data storage.
These use cases highlight Cassandra’s strengths in handling large data volumes with high availability and tunable consistency.
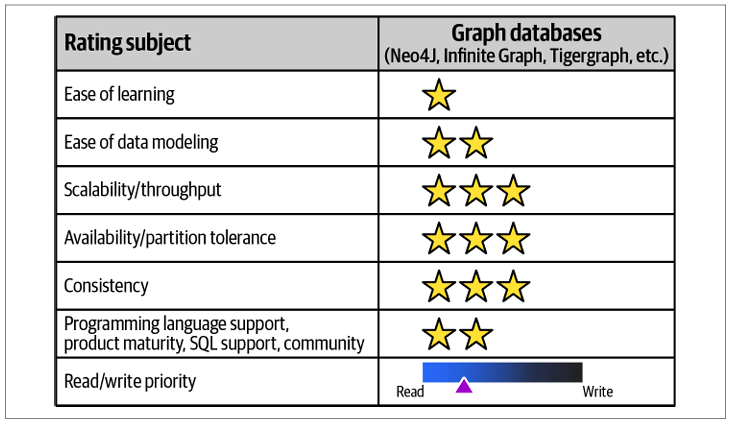
Graph Databases
Graph databases store data as nodes (entities) and edges (explicit relationships) with properties, allowing efficient traversal of connected data, unlike relational databases which infer relationships via keys. They have a steep learning curve and require careful data modeling but excel in read-heavy scenarios involving complex relationships. Graph databases support ACID transactions, have mature communities, and use query languages like Cypher and Gremlin. These databases are ideal for social networks, recommendation engines, fraud detection, and knowledge graphs where relationship analysis is key.
Compared to relational databases, graph databases are more flexible with dynamic schemas, provide faster multi-hop queries, and are optimized for highly connected data, while relational databases excel with structured data and simpler relationships.
Graph databases are used in many real-world applications such as:
- Customer 360 views that integrate every interaction and preference for personalized marketing.
- Fraud detection by mapping transactions and relationships to spot suspicious activity.
- Recommendation engines in e-commerce and streaming services that analyze user behavior for personalized suggestions.
- Supply chain management to visualize product, supplier, and logistics relationships for optimization.
- Network and IT operations management to map dependencies, monitor incidents, and plan capacity.
- Healthcare for patient data integration, drug discovery, and disease tracking.
- Social networks for community detection, trend analysis, and real-time event recommendations.
These examples show graph databases’ strength in handling complex, highly connected data for insights and real-time applications.
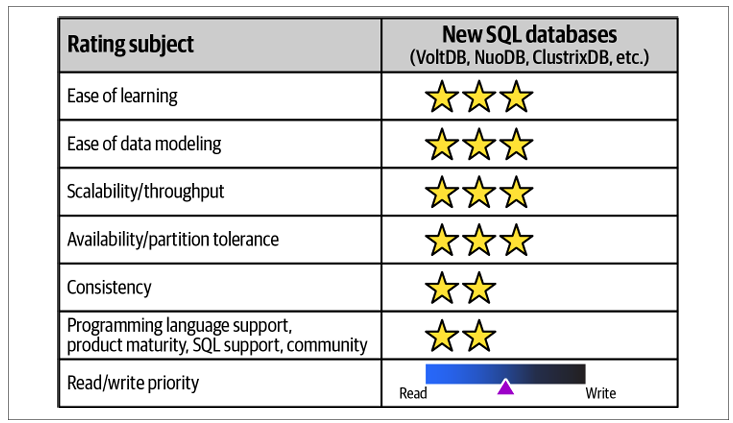
NewSQL Databases
NewSQL databases combine the scalability of NoSQL with the ACID guarantees and SQL interface of traditional relational databases. They support horizontal scaling with automated sharding, enabling multiple active nodes for high throughput and availability. This allows for strong consistency and easier transition for developers familiar with SQL and relational modeling. NewSQL databases are suitable for high-transaction workloads, global distributed cloud services, and scenarios requiring both OLTP and OLAP capabilities.
NewSQL databases are used in real-world scenarios such as:
- Real-time financial transactions where instant processing and strong consistency are critical, for example, global banks settling cross-border payments.
- E-commerce platforms handling massive spikes in traffic during peak events while maintaining order accuracy and fast processing, like Shopify during Black Friday.
- Supply chain and logistics systems tracking shipments and adjusting routes dynamically based on real-time data.
- Healthcare data management, supporting compliant and real-time patient data updates across departments.
- IoT and sensor data processing for smart cities and industrial automation with scalable, low-latency, and consistent data handling, exemplified by Google Cloud Spanner.
These use cases highlight NewSQL’s balance of scalability, ACID compliance, and SQL familiarity.
Cloud Native Databases
Cloud native databases are designed specifically for cloud environments, offering automatic scalability, high availability, and reduced operational burden. They typically leverage distributed architecture to scale horizontally, support automated backup and recovery, and integrate seamlessly with cloud storage and services. These databases provide cost efficiency through pay-as-you-go models and enable easy experimentation without upfront investments, but learning curves vary depending on the database and its data modeling approach. Popular examples include Snowflake, Amazon Redshift, Datomic, and Azure CosmosDB.
Cloud native databases are widely used in industries such as:
- Financial services, for managing high transaction volumes and real-time fraud detection.
- Healthcare, handling secure patient records and enabling real-time data analytics.
- Gaming, supporting scalable user data and delivering smooth online multiplayer experiences.
- Supply chain logistics, for real-time inventory tracking and demand forecasting.
- Education, managing student information and scaling online learning platforms.
- Social media, managing vast user-generated content and real-time data feeds.
- Utility management, monitoring resource consumption and integrating smart grid technologies.
- Retail, for inventory management and targeted marketing.
- Research and science, handling large datasets in fields like climate modeling and genomics.
Examples include Snowflake, Amazon Redshift, Datomic, and Azure CosmosDB, offering automated scaling, high availability, and simplified management in cloud environments.

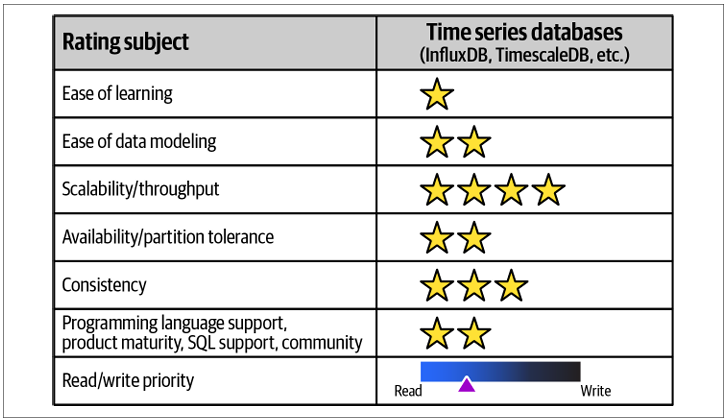
Time-Series Databases
Time-series databases are optimized for storing and analyzing data points tagged with timestamps, enabling tracking of changes over time. They are widely used for:
- Energy sector for smart grid optimization and renewable energy monitoring.
- Financial services for real-time risk assessment and algorithmic trading.
- Healthcare for remote patient monitoring and clinical research.
- Manufacturing for predictive maintenance and production optimization.
- Retail for customer footfall analysis and sales trend forecasting.
- Telecommunications for network performance monitoring and infrastructure planning.
- Transportation & logistics for route optimization and predictive vehicle maintenance.
- Entertainment & media for real-time content optimization and advertising strategy.
- Agriculture for crop monitoring and livestock management.
- Aerospace & aviation for aircraft health and flight scheduling optimization.
- Hospitality & tourism for booking trend analysis and demand forecasting.
- Maritime & shipping for vessel performance and port operations management.
- Urban planning for traffic management and population growth analysis.